| emLib | ||||||||||||||||||||
Rodi (P2P)
|
||||||||||||||||||||
| How to... | ||||||||||||||||||||
| Message board | ||||||||||||||||||||

|
Rodi Core
We have two separate binaries - Core and UI. Core supports all services from data search to crawling. UI provides ways to manage the Core. UI can be as simple as CLI or extensive graphic rich application. The following diagram shows Core subsystems:
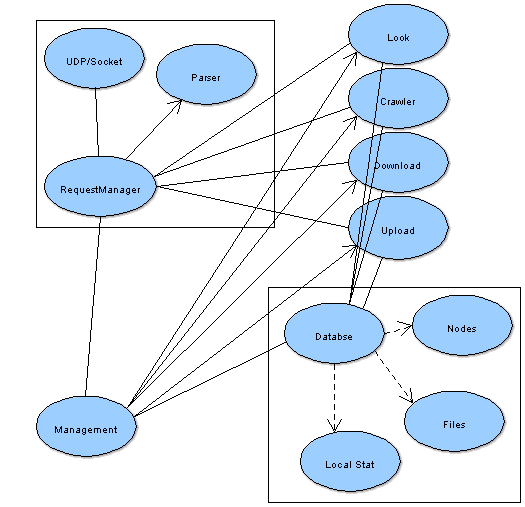
Data channel between Core and UI is UDP based
and secured with MD5 signature. In the first phase the system will not support
data encryption. Core will NOT provide Telnet interface, SNMP, etc. but instead
supports proprietary UDP based secured management protocol. After user starts
the core it try to find and read configuration from configuration file and
restore databases. If configuration not found the core stops and waits for
external application (UI) to make required configurations and start normal
operations. Core binary contains all required subsystems to download data, to
publish data and handle PUBLISH requests, to crawl the network, to upload the
data. Every one of the services can be switched on/off at any time. System opens
one UDP socket which is used for data, control and management.
Security Upstream. One possible solution is a secured registration
procedure which includes sending the client, via protected channel, 2
keys - client ID and tracker ID. Besides two keys supplied by the server,
there is a nickname chosen by client. When client initiates a transaction
it receives from the tracker a session ID - this is a third key used by
the client for client/host communication. Every request from the client
to the tracker contains the client nickname and the whole data set is
protected by MD5 including the client ID. However the client ID itself
is not sent at all. Likewise MD5 protection is used for every client request
to the host including tracker ID and session ID, but the tracker ID is
not sent over the network. Rodi assumes that all hosts have received the
tracker ID from the server and can calculate and check the MD5 of the
incoming packet. A correct tracker ID means that the client belongs to
the network. Combination of correct client ID and correct client name
means that the client specified a correct user name and has initial access
to the tracker.
Here is how different packets look for "client to tracker" and
"client to host" communication
| Client to tracker (for MD5 calculation) | Nickname | Client ID | Payload | N/U |
| Client to tracker (for sending) | Nickname | MD5 | Payload | N/U |
| Client to host (for MD5 calculation) | Tracker ID | Session ID | Nickname | Payload |
| Client to host (for sending) | MD5 | Session ID | Nickname | Payload |
Security Downstream. Is achieved similar to the client tracker, every packet is signed with MD5 calculated for the whole data set including tracker ID and session ID, but the sent packet only contains the session ID and payload. Upon receiving the packet client is expected to recover the initial packet using the stored tracker ID, calculate MD5 sum and compare with received sum. When communicating with the host the client expects that all packets arriving from the host are signed with MD5. Host's calculate MD5 using stored tracker ID and session ID, but sends only payload and MD5 sum. Here is how different packets look for "tracker to client" and "host to client" communication
| Tracker to client (for MD5 calculation) | Nickname | Client ID | Payload | N/U |
| Tracker to client(for sending) | Nickname | MD5 | Payload | N/U |
| Host to client(for MD5 calculation) | Tracker ID | Session ID | Nickname | Payload |
| Host to client(for sending) | MD5 | Session ID | Nickname | Payload |
Data encryption and how to fight P-Cube, Allot Communication, Expand Networks, Lancope Inc., Ellacoya Networks, Packeteer, Audiblemagic and similar solutions. One of the possible scenario is that the payload can be encrypted by the host before sending with a private key generated by the tracker. Client receives public key generated by the tracker as part of initial handshake. In a different approach the whole data packet can be encrypted in the data exchange between host and client and between client and tracker. Let's talk more about this. There are three separate problems the system can try to answer.
- Fighting traffic analyzers
- Protocol details/message exchange encryption
- Data protection
Apparently analyzers use some simple rules based on IP address and port number to collect the statistics or even drop the packets if ISP decides that the traffic is illegal or parasitic. In the more advanced analyzers "deep inspection of packets, including the identification of layer-7 patterns and sequences" is supported. P2P network can use some simple encoding algorithm, for example, XOR with long key. The strength of the scheme is regulated by the length of the key, frequent renewing and total number of keys. Let's assume that length of the key is 1M characters, there are 1M different keys - hosts generate different keys for the published files. At this point a reliable analyzer is expected to store and actively use about 1T characters of keys. Let's also suggest that keys are made accessible for registered clients using different protocols, like e-mail, FTP, HTTP, etc. Because normal high speed analyzer's are real-time embedded devices they can't reach the goal of collecting 1Tbytes of keys. See also Firewalls below.
It can also be argued that when an ISP sells a contract including 24/7 unlimited access at a specified bandwidth the customer's expectations are that network performance is application independent. An ISP can alternately issue a clear statement as part of the contract that, for example, P2P or proprietary VoIP applications have a low priority and services provided by ISP's mail server has higher priority.
Let's say that IP address and port number can not be recovered by an intercepting system, for example, as all nodes are behind PROXY servers supporting packet encryption in both directions. This approach brings additional costs related to the maintenance of PROXY servers. However, a P2P protocol can be defined in a way that helps ISP to recognize replicas and cache the data locally. For example, GetData request is a unique URL string and GetData response is a binary packet. Such anISP friendly approach could decrease network load significantly. There is a copyright issue here, because the cache is effectively part (or even all) of probably copyrighted material therefore the ISP's cache participates in the illegal sharing of copyrighted material. However, the liability issue is far from clear, because the ISP do not make any usage of the information in the cache besides facilitating the data transfer, these are the hosts who store and publish the material (see http://www.joltid.com/ http://zdnet.com.com/2100-1104_2-1027508.html http://assembler.law.cornell.edu/uscode title 17 for more on caching). A typical Internet browser stores information in a temporary files cache and it is not considered infringing on copyright laws.
Weak packet encryptionGoal of the weak payload encryption is to work around intelligent traffic analyzers looking for protocol signatures. Two schemes are suggested for packet encryption - torrent file oriented and seed oriented In both schemes only payload - bytes following 8 bytes request ID are encrypted. It does not create a problem because 64 bits request ID is generated locally by peer and essentially floating arbitrary random number. In both cases weak encryption is XOR - symmetrical, fast encryption algorithm.
In the torrent file oriented scheme weak encryption key - XOR, is part of the torrent file containing hashes of the data. Using of XOR key for both requests and acks is mandatory for all peers willing to participate in the data distribution. Rodi client opens torrent file and fetches encryption key. Rodi client encrypt all outgoing packets with this key. There is no way to distinguish between requests encrypted by different keys - key is not part of the payload and there is no any initial handshake-key exchange between the peers. This scheme assumes that all peers participate in distribution of only one file.
In the seed oriented scheme encryption key - XOR, is part of the host's (publisher) profile. Publisher advertises IP range/port/public key
combination on the identification server. Publisher posts XOR key of arbitrary length as an ASCII string.
When packet arrive to the publisher publisher runs decryption and attempts to parse the packet. If publisher finds that
the packet is not encrypted publisher can optionally attempt to parse unencrypted packet or can discard the packet.
On the client (downloader) side user adds host and host's encryption key to the data base of hosts. When downloade subsystem
issues request packet builder will look for the destination peer in the table of peers and if encryption is required packet builder
encrypts the payload.
Torrent oriented scheme is more flexible and will be implemented first. One of other options that encryption key can be published on the message board as part of the data advertisement or it can be the same permanent or randomly changed key used by this specific group of content publishers - publishers belonging to the same Rodi House.
Firewalls. Using any and only one IP port (for example, HTTP - 80) for the communication can help to fight some of the firewall configurations. Still in some cases stronger scheme should be implemented. The system can fake look&feel of real RTP or NFS packet - IP port number, Protocol type, etc. and destination node can still process the packet as regular. The system does not make use of TCP flow control features and essentially implement it's own packet delivery protocol (it can be, for example, similar to the Frame Relay protocol). In the first phase Rodi will fake RTP packets. It makes sense, because
- RTP runs over UDP, so it's natural for the UDP sockets created by the application and does not require native (non-Java) methods for implementation.
- RTP creates symmetrical traffic (upload is roughly equal to download) and adversary can't use statistical analysis to find nodes with abnormal behaviour
- It's easy for the receiver to work with both faked - containing RTP header, and regular packets. Receiver can make an attempt to read the packet as non-RTP and if fails (legal message event not found, etc) can try to start from 12 bytes offset (RTP header size)
- Payload is expected to contain binary data and spying equipment will not make an attempt to parse the data
Among other convenient UDP based protocols application can use is DNS (port 53). UDP packet payload for DNS queries starts with arbitrary 16 bits transaction ID followed by flags or so called opcode (0x0100 - Standard query), then 16 bits number of questions, three 16 bits fields (resource records) which are typically zero and in the end list of queries. DNS opcode of the query should be preserved to go through intelligent firewall. Size of UDP packet is limited by 512 bytes or less. DNS uses TCP for responses larger than 512 bytes. See RFC1035 for details.
IP network topology awareness, internal rounting protocol, looking for shortest pathTBD
IP Multicast. Next step from UDP seems obvious - using multicast for serving multiple clients. TBD
Packet structure. I want to
use min possible bytes and I want to make resolving of backward compatibility
issues easy. One of the approaches to the problem is XML formatted messages. For
example, typical LOOK request could look like this
<version>Rodi 0.8.5</version>
<id>23648236</id>
<request>
<event>LOOK</event>
<size>87</size>
<search>"Rodi 1.0"<search>
</request>
Solving backward and forward compatibility issues is easy. If you add a field - just add it. Previous versions of the code will ignore
unknown fields. New version should only care to set the field to some default value if arriving packet does not contain it. You can remove field
in new version of the software if there is some natural default value exists for the field. There is cost behind the solution - size of the packet. In
the example above we send about 120 bytes instead of 20 bytes of actual data. Encryption and sending of large packets consumes more bandwidth
and CPU. Another problem that XML packet can not be easy handled by network processor or ASIC.
We are going to choose different way. Packet carry must fields and information elements
(IE). Packet contains header (must fields) and list of information elements one
after another, where every IE contains at least 2 bytes - IE identifier and IE
size. Most significant bit of the IE identifier if 0 means that this IE is not
last in the packet and if one this IE is last in the list of IE. It gives us up to 127
different IEs for every event. You add and remove IEs to and from the message
definition easy like in XML, still overhead of the protocol remains low - 2 bytes for every IE.
| Packet ID | Header |
|
||||||
| 8 bytes |
|
|
Packet ID is 64 bits integer generated by the sender. Rodi client sends encrypted request lead by this number and expects to find this number in the ack. Encryption algorithm can be different for different hosts and packet ID is the only way for Rodi client to open the ack. Rodi client keeps list of pending requests. Request is removed from the list if ack arrives with correct packet ID or timeout expires.
Packet ID usually is a random number and can not be used by the traffic analyzer to distinguish the traffic. Payload of the requests sent to different destinations are encrypted with different keys using different algorithms. Packets can also be signed.
Least significant byte is first - little endian (Intel) byte order.
For example, Request Id IE looks like this 0x01 0x06 0x12 0xa3 0x40 0x9e, where 0x01 - IE Identifier, 0x06 - size of the IE (6 bytes),
0x9e40a312 - Request ID value. And with header 0x12 0x02 0x01 0x06 0x12 0xa3 0x40 0x9e, where 0x12 - message event, 0x02 - size
of the header (2 bytes), 0x01 - IE identifier (Request ID), 0x06 - IE size, 0x9e40a312 - Request ID value.
Request Manager
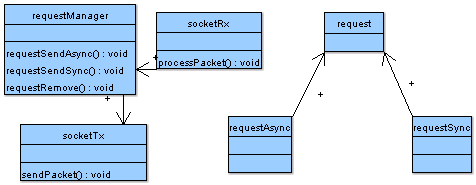
Application thread can
send synchronous request and asynchronous requests. In case of the former the thread will be suspended until one of the
two conditions not met - response from the remote peer arrived or specified by the calling thread timeout expired.
In all cases requestManager allocates new request structure from the pool of free requests. There are two
separate pools of requests - poolReqSync and poolReqAsync. Pools are implemented as cyclic buffers and created in the initialization
time. Sent request is called pending request. requestManager
keeps all pending requests in the array of pending requests - pendingRequests.pendingRequests.size is equal to (poolReqSync.size + poolReqAsync.size)/(hash ratio)
Size of pools depends on the available upstream bandwidth, packet size and delay. Maximum number of pending requests is
(Bandwidth/packet size) * delay. Packet size is expected to be between 64 and 256 bytes, typical network delay is less than 3s (it's more like
0.3 - 1s range)
requestManager signs the packet with MD5 (if needed) and place unique 32bits identifier - requestId. requestManager expects that the remote peer will response with the packet containing exactly the same identifier. requestManager use this identifier to find pending request in the pendingRequests array and forward the response to the relevant subsystem.
- How requestManager generates the requestId ?
It can be, for example just a counter of requests starting from zero, or result of random generator, or both - most significant nibble is derived from the counter and least significant generated by random generator. - How requestManager finds entry in the pendingRequests array ?
requestId is used as an argument for hash function. In similar way requestManager stores requests in the array - it calls hash function for the generated requestId and gets array index where request should be kept.
Message parsing, verification, building
Different approaches exist to the problem of message parsing. What I am looking for is very RAM and CPU efficient scheme, which can be easily ported
for any OO environment.
In one of the possible solutions when raw data packet arrives object factory (special class) is called to parse and verify the data and create
a new object. Type of the object depends on the packet data, but typically all types/classes belong to the same inheritance tree rooted from, like
on the diagram below
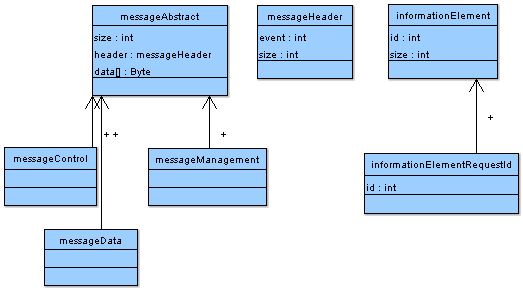
When preparing packet application creates object of required type, for example messageResponseLookAck, add to the object list all required
information elements and calls packet factory to generate raw data array. While the whole process looks very nice and logical and very Object Oriented
it has it's flows and the major one - performance. Let's assume that factory use pools of ready objects (overloading operator new) and this way
avoids new/delete operators performance penalty. Still some questions remain:
- How (if at all) we keep incoming raw data.
- What we are going to do with large data packets where most of the payload is raw data.
- If application looks for some specific IE it should iterate through the list of IEs until it finds one. isn't it faster to look for IE id directly in the raw data and call some static method returning all required fields of the IE.
- When application generates raw data packet from the object how it knows what block should be allocated without additional iteration through the list of IEs and calculating data size.
Incoming. Message object contains reference to the header and reference to the raw data packet. After packet verification and parsing object contains list of IEs. IE among other property fields keeps offset in the packet and reference to the array.
Outgoing. Packet builder creates required message and adds IEs one after another to the list of IEs of the message. Every time packet builder adds a new IE it calculates required space and updates message size field. When the application makes a final call to release the raw data packet packet builder allocates array from the data pool and calls message header and IE methods to construct raw data.
The following is an attempt (in the spirit of best effort communication) to provide an overall picture of class hierarchy.
Message is just a place holder for references to the message header and list of IEs. IE class itself has an interface supporting linked list. Message header and IE inherit from the same parent - MessageAtom and implement interfaces required by Object Factory and Packet Builder. Among the methods required
- getId() - returns IE Id
- getSize() - return IE/header/message size
- setRawData() - fills the specified array at specified offset with raw data
- getOffset() - returns offset in the packet from which IE/header stats
- ...
- Ignore unknown/unrecognized IEs.
- If packet does not contain IE which is required by the context object factory ignores the fact and all logic handling the case is placed in the higher application levels.
- If IE data is illegal/corrupted skip it - data related to the IE is ignored
- Parser makes effort to stay in sync (optionally). It means that if parser encounters corrupted IE parser can try to find next valid IE id/size pair - return to sync.
Object Factory and Packet Builder. Number of different concepts are used when approaching the problem of handling of
big chunks of data.
System incoming flow looks like
Socket Rx -> Parsing And Verification
Main intention should be to free socket thread immediately and handle the packet in the context of different thread,
supposedly running in the lower than SRX priority. It means that PAV is a task. Packet processor is implemented as a thread waiting on mailbox.
Packet processor expects that block it received from the Socket RX was allocated from the well known
pool and should be eventually returned to this pool if packet processor decides to drop the packet.
Packet processor is optimistic and start to build object from the first atom - header, if found valid.
If at some point verification fails and the whole packet declared corrupt Packet processor will release all previously allocated data,
which includes block allcated by Socket RX and all atoms used - header and IEs. Parsing flow is fairly simple
- Decryption. Packet processor looks for packet ID of the packet in the data base of sent packets. Data base contains reference to the object decryting the packet. In trivial case this is dummy decryption - does nothing with the data.
- Find header, fetch Event field
- Iterate through all IEs of the packet adding newly allocated IE objects to the message list of IEs. Naturally there is a pool of IE and all IE will be allocated from this pool. Because in Java there is no way to map object to raw data array, like C++ type casting from unsigned char * to myObjectType * without costly serialization procedure the only way to organize such pool is to create separate pools for all existing types of IEs. C++ application can create pool of row blocks with block size equal or larger than max size of IE and reload operator new(). Pools are organized as stacks where block allocation is pop and block release is push. If stacks are created bigger than number of IE created application if need arise can in runtime create (allocate from free RAM) new IE and add to the stack, though this kind of solutions is not recommended. Parsing and verification are done simultaneously and result is a message object containing reference to the data packet, list of IE, message header.
- The last step is forwarding the message to the RM - thread waiting on the mailbox.
Now let's see what happens in the packet builder - upstream link. Application has a message object from which data packet should be generated preferably without costly memcpy's. Currently application makes one memcpy when reading data from file and placing into the packet.
Packet builder sets packet id in the first 8 bytes of the packet. Packet builder calls message setup method to build binary packet. Message setup calls all information elements one after another. Packet builder then runs encryption for the data. Packet ID is left unencrypted. The packet is sent out by the application - synchronous call to Socket Tx. Packet builder add packet ID and and correspondent decryption object to the list of packet IDs. Packet processor is expected to look on the list for reference to the decryption object when ack arrives.
Message object calls signature information element last. Signature information element setup itself in the packet using zeros for the packet hash field. Signature information element then calculates hash of the whole packet including packet ID (packet ID is set by packet builder), encrypts the resulting hash and copy the result to the packet hash field.
Management. Rodi core provides access to the internal data bases and management functions. Core opens management socket and waits for requests from the management. Management can be just a simple CLI or graphic and color rich GUI application and can be written using any language and can run on any system. This project develops two interfaces - CLI and light GUI. CLI provides menus to print current statistics, configure system parameters, start/stop upload/download, publish data, etc.
GUI resembles CLI in the look&feel. GUI is table based, JDK 1.2 compliant (no Swing elements), light weight, distributed as JAR file and source (click example). Binary code limitations - GUI is not expected to be larger than the core. Because the management interface is provided through socket, browser based interfaces can be easily developed. User's fill the address line of the browser with something like http:\\localhost:6969. Browser downloads the GUI code from the engine and starts it. Any language can be used for GUI - HTML, JavaScript, Java, Flash.
Core manager is implemented as a single high priority thread in the infinite loop blocked by call to the mailbox. Core Manager or Server waits for requests. Core Manager serves one request after another. Core Manager assumes that arriving packets are checked by packet processor against existig data base of authorized users - pairs of nickname and public key. Packet processor drops unauthorized packets. Deliberate attacks against Core Manager can be prevented by snubbing engine.
Core Manager generates 64 bits session ID and sends current session ID with each and every request ack. Core Manager expects to find in the next request this exact session ID. Core Manager can and will change session ID from time to time for the running sessions challenging Remote Manager to recalculate security information element.
On the other side of the system is Remote Manager or Client. Client uses it's private key and nickname to generate security information element and adds this information elemenet to each and every request. Session ID generated by the Core Manager is part of each and every request sent by Remote Manager. It prevents the scenario when adversary sends the same request to other Rodi clients.
Similar to the Core Manager - Remote Manager generates 64 bits session ID and sends it with each and every request. Remote Manager expects to find it's session ID in all request acks arrived from the Remote Manager.
Security information element is mandatory in all packest and contains nickname of the peer and MD5 of the packet encrypted with peer's private key.
Remote Manager initiates session by sending login request with it's own session ID. The packet is signed with security information element. Core Manager
receives the packet from the packet processor, registrates new session, generates session ID and akcs the request with 'wrong session' status and local
session ID. Remote Manager issues new login request containing both remote and local session IDs and signed with security information element.
The session is established.
Management protocol on the side of the Remote Manager works as asynchronous RPC. Remote Manager is free to issue multpile requests to the Remote Manager. Remote Manager keeps list of pending requests. Remote Manager does not assume that Core Manager has any history of the requests. Core Manager always sends ack to to the served request. Ack can optionally contain data, status, etc.
Exact structure of the management request is not known to the transport protocol - Rodi. Management packet contains
- message header
- request ID information element
- session ID information element
- array information element carrying payload
- security information element
In the proposed implemenation 32 bits request ID is a mandatory field in the payload. Remote Manager generates unique 32 bits request ID to distinguish between requests. Core Manaqer adds copy of the request ID to the sent ack.
When ack from Core Manager arrives Remote Manager looks for the request ID on the list of pending request IDs. List of request IDs is implemented as a hash table. If request ID is found Core Manager removes the request from the list and forwards the ack to the application level. In the backgorun Core Manager runs thread checking requests timeout and notifying the application.
Management paylod contains at least one field - 16 bits event. All requests are acknowledged by the Core Manager. If it's required Core Manager sends data in the acknowledge.
Implementation details Naturally everything starts in the class Start file Start.java. This class extends Applet btu also contains method main() so JAR can be used both as applet (run in the context of internet browser) and standalone application. It is going to remain this way. When Rodi runs as a standalone application the performance is somewhat better because there is no overhead of Java security layer. All initialization calls are done in the method init(). I make extensive use of global variables. All global variables are placed in the class Resources file Resources.java. Specifically reference to the Look thread, Log, CLI, etc.
CLI use the Log for output which can be changed in the future. One of the parameters of CLI is
output stream which is any class providing print(String) method. CLI does not care where input comes from.
method Start.init() spawns two socket threads - socketRx and socketTx. socketRx is high priority thread which should free the datagram socket
as quick as possible. socketRx forwards all incoming packets to the daemonRx in which context all packet processing takes place. socketTx is
a class (not thread) providing access to the datagram socket for application services like search engine (Look).
All methods and fields of the class Resources are static and most of them are public. It keeps reference to the datagram socket (the system
needs only one socket for communication), debug statistics, reference to the application subsystems like Look, RxDaemon, socketRx, socketTx, etc.
There are plenty of debug counters in the code. One can argue that I am obsessed with debug counters. I would say that there are never enough.
Usually I prefer to increment some global counter and return error (null or -1) instead throwing exception. For example, class Pool besides
regular and expectable size and number of free blocks indicators has also number of allocation and release attempts and number of failures.
Similarly class Mailbox increments a counter every time mail sent, received, etc. Class Look today provides about dosen of different inidicators and
counters including byte and packet rate, number of requests sent, etc.
Rx and Tx socket provide byte and packet rate indicators. The implementaion is fairly simple. Object upon creation starts 10s timer. Once the timer
expires number of sent in the last 10s bytes/packets divided by timeout (10s) and stored in the correspondent indicator, for example
indicator Resources.statisticsSocketRx.byteRate. User can access the counters through CLI, for example, command [dbg rx] will print
current socketRx statisitics.
Rodi chat
Any Rodi peer can run chat room. When Rodi client creates new chat room it generates 128 bits identifier. With every chat room is assotiated 128bits identifier.
There is also name (nickname of the chat room) and description.
Chat room host forwards all messages to the participating chatters. No IPs are sent, only nicknames. Chat room host can choose between two models.
In one chat room engine always attempts to send acknowledge to the chatters.
In the second model chat room is only a collector of messages.
Rodi chat supports IP scan. Chat room host can advertise IP range and port number where chat room (most likely
message collector) can be found. Peers will send messages to all advertised IPs. Peers can find chat rooms using regular LOOK.
Chat rooms can be public and private To join public chat room peer sends signed with it's private key string "join+nickname+public key". Public chat room checks uniqueness of the nickname and adds public key to the list of participating peers. To join private chat room peer sends the same message, but this time chat room only logs request. It will require manual intervention to add the peer to the list of participating chatters.
Packets can be encrypted. Chat room owner should advertise enctyption algorithm and send keys to the participating peers.
Participating peer can choose between two models. In the first peer only sends packets with spoofed IP. In the other peer sends packets with correct IP source in the IP header or in the encrypted payload.
Participating peer or chatter can use two PCs - one to send messages and the other monitoring the chat room.
Packet rate control Rodi does not use TCP, still it needs some algorithm to prevent congestion on the receiving side. Packet rate control can be viewed as a black box with limited number of inputs and outputs.
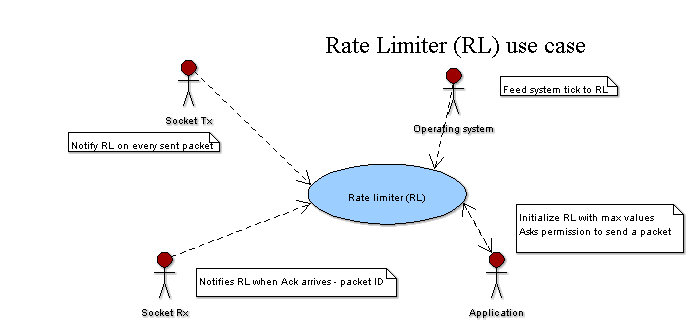
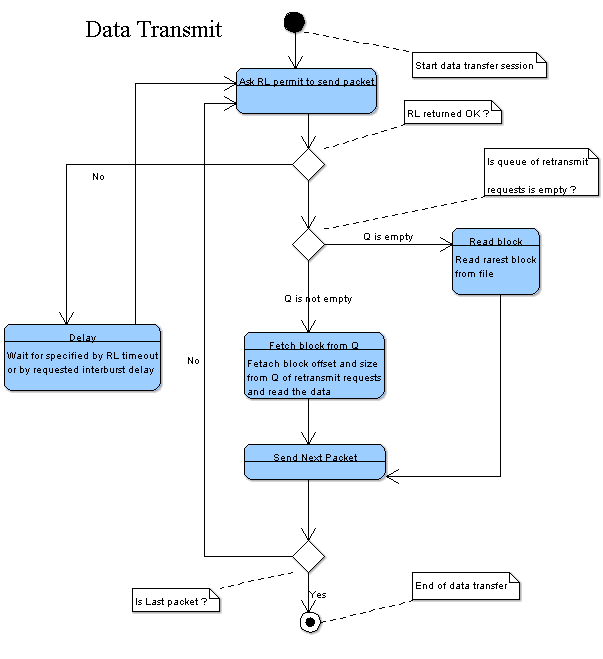
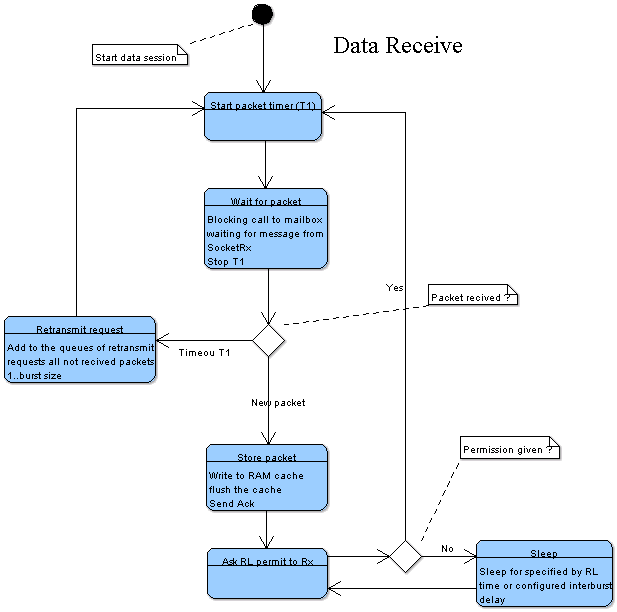
Application running data transfer asks permission of Rate Limiter (RL) every time it should send a packet or enter receive. Currently I see two levels of RL's - one RL for every session and one global or system level RL. Session RL returns logical AND of it's own state and response of the system level RL.
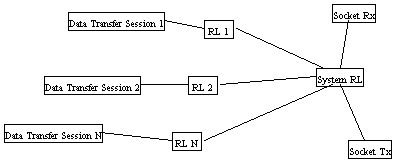
SocketRx and SocketTx threads feed the System level RL and thread handling data session rx/tx operations feeds the correspondent session RL. RL contains all logic related to the dynamic fine tuning of the upstream and downstream. Every RL maintains packet shceduler - array where every entry contains burst size. Size of the array is defined in number of system ticks. For example, array
0,0,1,0,0,1,0,0,...
Download&Upload
Let's make reasonable assumptions regarding behaviour of the downloader. Normally downloader is interested to get rarest blocks first.
I let downloaders to decide what block is rarest in the network. I define information element Map which is a bit map of blocks. When
blosk is present the corresponding bit is 1, if there is no such blok the bit is zero. Number of bits in the map is equal to number
of blocks.
Downloader starts with empty local blocks map - all bits are zero. Downloader is expected to collect maps received from the peers and slowly build the full map of blocks presenting in the nework. There are two sources of the maps. The first source is responses to the LOOK request. All paritcipating peers are expecting to send MAP IE containing local map together with LOOK ACK if LOOK ACK contains STATUS IE FILE_FOUND. The other source of the maps is GET DATA requests and GET DATA ACKs. Downloader sends GET DATA request containing local blocks map - shows the blocks with correct hash.
Downloader constantly updates the database of the maps calculating availability of every block. Availabilty of a block is summ of "1s" in the collected maps. Rarest block is the one with lowest summ. Availability of data is calculated as availability of rarest block of the data.
Code of downloader can be and hopefully will be customized by any netowrk participant in the way to promise best possible transfer rates. There is little doubt that in some algorithms peers will try to spam the uploaders with GET DATA requests in attempt to get upstream slot the moment uploader closes previous session. This is not going to work, though. Uploader collect all statistics related to the peer including number of GET DATA requests and will ban spammers for some period of time.
Uploader just delivers requested blocks and provide list of peers in the GET DATA ACK status BUSY and does not contain any logic related to the rarest block first, etc. Optionally uploader can implement super seed mode, but from the tests it appears that there is no reason to do it - good downloading algorithms will tend to send requests for rarest blocks first, because this is a smart thing to do.
Good uploading algorithm should prioritize 'well' behaving peers. Good peer, for example, is a peer with high upload/download ratio. Uploader can upload one or two blocks and then ban the peer until it uploads similar number of blocks. The only reliable information for these decisions is the information collected locally. Global data base of all known peers keeps statistics between download/upload sessions.
Uploader has two limits for the upstream - maximum number of simultaneously existing sessions and total bandwidth. Similarly downloader limits the downstream by number of sessions and total bandwidth.
Objects of class Download contain a thread and a single shared instance of RequestManager. Class Download has a static method notify (similar to class Look). Class PacketProcessor calls Download.notify every time a packet arrives carring GET DATA ACK message header. Method notify takes the message ID and goes to the RequestManager to find the exact GET DATA request this GET DATA ACK for. If there is no pending request with such request ID method notify updates statistics and drops the packet. If corresponding request ID found method notify forwards message to mailbox of the download threads which issued the original request. Download thread does not expect that there is only one GET DATA ACK for every GET DATA. If GET DATA ACK contains only part of the requested data Download will add request to the RequestManager with the same request ID.
GET DATA request contains information elements describing offset and size of the requested block, packet size, burst size, interburst and interpacket delay. Download assumes that GET DATA ACK packets will arrive according to the specified parameters or slower.
Download can issue mulitple GET DATA requests, but not to the same peer.
Download will spawn LOOK procedure for the downloading file periodically in attempt to find new peers and update blocks map. Pay attention that LOOK packets should not be issued tooo frequently because peers can start to drop the packets (all packets) from the spaming node. 5-10 min period is considered reasonable depending on the file size and results of the previous LOOK requests.
When GET DATA ACK arrives download thread updates internal blocks map. Internal blocks map use much smaller block size than Map IE - in the range 64-256 Kbytes. Retransmission requests are to be issued in this resolutuon. Initial GET DATA request can be issued for the whole 4MB block.
Download thread fetches the data from the arrived packet and writes data to the disk. If download thread discovers from the internal map that whole 4Mbytes block received it calculates the hash and compares with the hash found in the hash table of blocks (if available). Download thread discards 4MB block if hash check fails. Download thread updates statistics for the relevant peer to avoid sending GET DATA requests (and any other requests) to this peer in the future. The peer remains banned for some period of time or forever depending on the application.
Menu download in the CLI provides following commands
- Table with download statistics
- Download internal blocks map(s)
- Start/Stop/Pause download for file found in latest Look
- Table with download status - number of pending requests, file availability, what is done, estimated time to completion, average transfer rate
- Set upstream/downstream rate limiters
- TBD
Snubbing Algortithm Every packet and every request has price because processing of every request carry some costs in terms of upstream, downstream and CPU consumption. There are two kinds of packets - packets which are usefull for peer and packets which are not. Every peer collects and keeps statistics for all other peers with how many usefull packets it recieved and how many usefull packets it sent. Before processing next request from a remote peer Rodi client checks the mark of the remote peer and if it's too low drops the packet.
Mark is a function of number of usefull packets and not usefull packets. There are different kinds of packets - packets which consume bandwidth, packets which are costly for CPU, etc. Different kinds of packets have different weight in the resulting mark
NAT traversal TBD read STUN RFC There are four major types of the NATs (source - STUN RFC and wikipedia.com)
- full cone NAT - all requests from the same internal IP address and port are mapped to the same external IP address and port. any external host can send a packet to the internal host, by sending a packet to the mapped external address.
- symmetric NAT - all requests from the same internal IP address and port, to a specific destination IP address and port, are mapped to the same external IP address and port. If the same host sends a packet with the same source address and port, but to a different destination, a different mapping is used. only the external host that receives a packet can send a UDP packet back to the internal host.
- restricted cone NAT - all requests from the same internal IP address and port are mapped to the same external IP address and port. an external host (with IP address X) can send a packet to the internal host only if the internal host had previously sent a packet to IP address X
- port restricted cone NAT - all requests from the same internal IP address and port are mapped to the same external IP address and port. an external host can send a packet, with source IP address X and source port P, to the internal host only if the internal host had previously sent a packet to IP address X and port P.
The suggested procedure assumes that symmetric NAT chooses external ports one after another. For example, NAT can
allocate ports starting from 1024 and continue 1025, ...
Client when contacting such peer runs port scan starting from the most
probable port. In the same time client behind symmetric NAT punches the NAT. If both peers are behind symmetric NATs both will run
port scan to discover external port numbers.
For all other types of NATs there is no need for any assumptions.
Upon initialization client attempts to discover what type of NAT is in use. It requires help of the external server - NAT
traversal server.
Server opens three UDP ports, forwards them in NAT and waits for incoming NAT penetration packets. When a packet arrives server
responds with the NAT penetration reply. In the payload reply contains IP address and port as server sees them according to the UDP
header. Additonally server puts unique key into the payload which allows to access the log of the session. Server keeps log of all
arrived packets and provides HTTP access to the XML file containing the log. This log can be used for debug or for discovery of
peers able to spoof IP address.
Rodi NAT traversal server can require from the clients to sign all packets to limit access to the database and enforce application dependent
rules. This requirement assumes that Rodi NAT traversal server keeps public keys of all peers in the Rodi hub.
Client sends NAT penetration packet to all server ports. In the payload client puts unique key, local IP address and IP port.
Client expects that the server in the reply (in three replys from three different ports) will copy the unique key and put client's
external IP address and IP port. When client recieves the replys client will analyse them.
The following are possible outcomes
- External IP and port are the same in all replys.
- External IP and port are not the same. External port in the first reply is equal to the local port. Replys 2 and 3 contain sequential ports.
- External IP and port are not the same. External port in the first reply is not equal to the local port. Replys 1, 2 and 3 contain sequential ports.
- External IP and port are not the same. Replys 1, 2 and 3 contain randomly choosen ports.
Client has to distinguish between full cone NAT and port restricted NAT. In both cases NAT maps internal port to the same external port for all connections. Client asks via NAT traversal server some other NAT traversal servers to send a packet. If the packet goes through the client is behind full cone NAT. If external peer fails to deliver the packet client assumes port restricted NAT.
With every Look request/Data request client advertise discovered external IP address and port, NAT type, IP address of the NAT traversal server. This is optional for clients behind full cone NAT or clients without NAT or clients with forwarded port. If client does not advertise NAT type and external IP address remote peers assume that this client can be contacted directly from any IP address.
Clients behind symmetric NAT and behind restricted NAT keep one connection with the server alive by sending periodically NAT penetration message. To reduce load of the NAT traversal server only clients behind symmetric NATs and restricted NATs are allowed to keep connecitons. NAT traversal server can enforce this rule by blocking the IP address.
Client behind non-symmetric NAT is allowed to repeat the procedure of NAT discovery from time to time.
Let's say that peer A learned IP address of peer B and type of the NAT of peer B is a symmetric NAT. Peer A sends message to the NAT traversal server that A attempts to contact B. NAT traversal server should respond with reply Ok if client B exists or Fail if the server does not know client B. If NAT traversal server knows client B the server forwards packet from A to B. B receives the packet, sends NAT penetration packet to server, discovers external port and sends NAT penetration packet to A - B punches the NAT. The server sends external port of B to A in Ok reply. A uses external port of B as a starting point for penetration port scan of B.
NAT traversal takes time and is not always possible. Subsystem (for example, Look) willing to send a request to the peer behind symmetric NAT will use asynchronous interface. Status of the NAT penetration will be delivered by the API asynchronously using provided by the subsystem callback. The subsystem is responsible for closing the NAT penetration when there is no need to keep connection with the peer.
Port scan consumes upstream of the peer running the scan and downstream of the destination peer. Client will choose peers behind symmetric NAT as a last option when there are no other peers or all other peers are busy and upstream of the client is not in use.
Using of the NAT traversal server is optional. List of the Rodi NAT traversal servers is available as an XML file from regular HTTP server.
Let's say that A attempts to contact B behind restricted or symmteric NAT. B connected to the NAT traversal server S. A sends Forward request to S. Payload of the Forward request contains command Wake Up and IP address and port of B. S adds IP address and port of A and forwards Wake Up message to B. B sends Forward request to S with payload containing Wake Up Ack and IP address and port of A. S forwards the request to A. B can send Wake Up Ack directly to A if A is not behind restricted NAT.
When A gets Wake Up Ack A starts port scan of B. When B gets Wake Up request B starts port scan of A.
Depending on the type of the NATs A and B will execute full or partial port scans and eventually discover external port number. When A
discovers port number it sends Forward request to S with payload containing command Stop. S forwards command Stop to B. B stops port scan,
releases all allocted for session with A resources and sends Forward request with payload Stop Ack to S. S forwards Stop Ack to A.
A is expected to keep the hole in the NAT of B using Ping message sent directly to B.
Crystalization Let's say that peer P1 has block m and does not have block n (m, n), let's say also that peer P2 can be described by pair (n, m) - has block n and does not have block m. It appears that if two such peers find each other quickly and establish connection that would reduce overhead and improve overall performance of the network.
We call the process of establishing of such pairs - crystalization. In the beginning we see liquid - chaotic movement of molecules. With time peers learn maps of each other and connect to each other - crystalization phase. Good cooperation algorithm tends to crystalize the system in full - create one crystall where all peers are locked and satisfied and do not attempt to establish new connections.
One of the proposed solutons of the problem that in the GET DATA ACK status BUSY peer can add estimated time when the upstream is getting free. Let's say that P1 sends GET DATA request for block n to P2. P2 can not open upstream immediately because it's busy serving other peers, but P2 wants to help P1, because P1 has a block which P2 does not - block m. P2 wants to be cooperative. P2 estimates - best effort guess - for how long time P1 should wait before it gets data from P2, sends the result in the GET DATA ACK message and puts P1 onto the waiting list. P1 is connected to the network for some time already and can estimate typical time which it takes to find free uploader with requierd blocks. P1 compares the timeout specified by P2 with the estimated and if the deal is good starts timer. When the timer expires P1 trys to send new GET DATA request to P2.
P2 keeps free upstream for the P1 for some limited and relatively short time. If P1 fails to send packet P2 will use the upstream to serve other peers.
Bouncer Bouncer is a thread waiting on socket rx. When a packet arrives bouncer sends the packet to other IP address. Bouncer is controled by rules. Rule contains following fields
| Rx IP address and port to bind datagram port to | Mandatory | IP interface for incoming packets. Downloaders will send packets to this address and port |
| Tx IP address and port to bind datagram port to | Optional | This is the interface bouncer use to send packets (can be dummy IP interface TBD). If this parameter is not specified bouncer will use the same IP interface and IP port for Rx and Tx operations |
| Destination IP address and port | Mandatory | This is the address where bouncer forwards the packets to, for example IP address of publisher or another bouncer |
| Rate limiter | Optional | If specicfied will limit number of served packets/bytes |
| Tx Signature | Optional | This is a secret word used in calculating MD5 for every packet bouncer forwards |
| Rx Signature | Optional | This is a secret word used in calculating MD5 for every packet bouncer receives |
we need to install open source security server to generate unique IDs, private and public keys and signatures. Rodi network needs some centralized system of exchange of keys.
To support downloaders spoofing IP source bouncer will ignore IP source and look only for the destination IP port. If packet contains PEER IE in the payload bouncer will use this IP port and IP address to find forwarding rule.
Bouncer will forward only Rodi control packets. Bouncer optionally can enforce this by analyzing the packet payload.
Usefull bouncer can be able to handle at least 1-2K packets/s. Such bouncer can serve group of may be 100-200 downloaders.
Data transfer
Naive implementation of data transfer plugin. Will be used for debug purposes and until
UDT like plugin is not available
'send request - wait for data' action in the download direction and 'send steady stream'
in the upload direction. very basic flow control is implemented on the uploader side - no flow control
at all.
i assume that packet loss is zero and shared upstream is significanlty smaller than downstream.
If block fails downloading peer will issue separate requests for the missing chunks.
Packet structure:
- Event - 1 byte (mandatory)
- Payload size - 2 bytes (mandatory)
- Chunk offset - 8 bytes (optional)
- Data (optional)
- GET - sent by downloading peer if a chunk is not recieved
- DATA - sent by uploader
If for 30s (timer T2) there is no new packets arrive downloader assumes that uploader closed the data transfer session.
When uploader receives first GET it assumes that downloader has infinite bandwidth and streams the data to the receiver. Uploader sends all chunks as quick as possible. In the best case scenario only one GET (first) arrives to the uploader. After completion uploader starts T2 and if T2 expires close the session. If GET from the downloader arrives uploader restarts T2 and serves retransmission request.
Uploader is free to choose the chunk size, but chunk size will not be smaller than 1024 bytes and will always be a power of two - 1024, 2048, 4096, ...
Information elements
Search (Look)
In the first phase only one look can be started. If LOOK request contans IP address/IP port publisher will use this address as a destination
instead source IP from the IP packet header. There is an optional periodic 'keep alive' look request a peer sends to a host to prevent
timeout of the entry in the host's table of active peers.
request contains the following IEs
| Message header - 1 | Mandatory | Message event 1 |
| Search pattern | Mandatory | |
| IP address and port | Optional | |
| Message ID | Mandatory |
Look Ack
In the first phase only one look can be started. If IP address/IP port is present in the payload client (receiver) shall use this address instead of
regular IP address from IP packet header. Source IP in the IP header is not reliable and can be intentionally spoofed by the publisher.
IP addres/IP port in the payload can be address of the publisher or one of the traffic bouncers chosen by a publishers. Publishers can implement
different algorithms when choosing bouncers. In the most simple scenario a publisher chooses arbitrary IP from the pool of public bouncers. Pay
attention that bouncer usually will NOT proxy data, but only control messages
More details are required here.
request contains following IEs
| Message header - 2 | Mandatory | Message event 2 |
| Message ID | Mandatory | |
| Status | Mandatory | |
| IP address and port | Optional, multiple | |
| Blocks map | Optional, multiple | |
| You are | Optional |
Data Request (Get Data)
If GET DATA request contans IP address/IP port publisher will use this address
as a destination instead source IP from the IP packet header.
Publisher initiates session and generates local session ID. Both peers store local and remote session IDs
request contains the following IEs
| Message header | Mandatory | Message event 3 |
| Message ID | Mandatory | |
| IP address and port | Optional | |
| Session ID | Mandatory | Peer will use this field in the data transfer protocol |
| Protocol ID | Mandatory | Data transfer protocol to use |
| Blocks map | Optional | Local map of blocks |
| Connection | Optional | Connection parameters |
| Block | Mandatory | Size and offset of the block to transfer |
Data Request Ack (Get Data acknowledge)
Peer sendign this message generate local session ID. Session ID is part of the message only if Status IE is BLOCK FOUND
message contains the following IEs
| Message header - 4 | Mandatory | Message event 4 |
| Message ID | Mandatory | |
| Status | Mandatory | If Status is not OK this is the last IE of the message |
| Session ID | Mandatory | |
| Block | Mandatory | |
| IP address and port | Optional | |
| Blocks map | Mandatory |
Data Transfer
Carrys data transfer protocol packets
message contains the following IEs
| Message header - 5 | Mandatory | Message event 5 |
| Protocol ID | Mandatory | |
| Session ID | Mandatory | |
| Array | Mandatory | Data transfer protocol packet. Can carry separate encryption, authorization, etc. besides and above of what Rodi protocol provides |
Management request
Carrys management requests and acks, for example, between GUI and Rodi client
message contains the following IEs
| Message header - 7 | Mandatory | Message event 7 |
| Protocol ID | Mandatory | Rodi client can support different management protocols, including Java RMI, RPC, SNMP, etc. |
| Array | Mandatory | Management protocol packet. Can carry separate encryption, authorization, etc. besides and above of what Rodi protocol provides |
| Signature | Mandatory | All management packets are signed |
NAT traversal
Carrys NAT traversal messages between clients and between client and Rodi NAT traversal server
message contains the following IEs
| Message header - 17 | Mandatory | Message event 17 |
| Message ID | Mandatory | |
| NAT traversal | Mandatory | NAT traversal IE containing command and required information like IP address, port, type of the NAT, etc. |
Crawler
Download
Upload
Database
| Message board |
| Home |